Data Mesh verspricht, die Datenverantwortung zu dezentralisieren, indem Fachbereiche ihre eigenen Data Products bereitstellen. In der Theorie klingt das überzeugend: schnellere Umsetzung, höhere Relevanz, mehr Ownership. Doch obwohl das Modell die Zusammenarbeit eigentlich erleichtern soll, fühlen sich viele Organisationen schnell überfordert – mit persönlichen Folgen wie Stress, Spannungen im Team und Frustration.
Domänenteams sollen plötzlich wie Engineers arbeiten: Sie sollen Datenpipelines bauen, Dokumentation pflegen, Sicherheitsregeln umsetzen und Governance-Vorgaben einhalten – zusätzlich zu ihren eigentlichen Business-Aufgaben. Die meisten sind dafür nicht ausgebildet. Und selbst wenn doch, führt die kognitive Überlastung oft zum Stillstand, untergräbt das Vertrauen ins Modell und erzeugt das Gefühl, im Rückstand zu sein, während andere vorankommen.
Dieser Beitrag zeigt, wie man Data Mesh praktisch zum Laufen bringt – indem man Fachbereichs-Teams mit den richtigen Tools und Automatisierungen ausstattet, damit sie als Citizen Developer agieren können, anstatt unfreiwillig zum Engineer zu werden. Ohne diesen Support entstehen schnell inkonsistente Data Products, Schatten-IT und Governance-Lücken – und die ursprüngliche Vision des Data Mesh wird konterkariert.
Was von Fachbereichs-Teams erwartet wird
In vielen Data-Mesh-Umsetzungen übernehmen fachbereichsnahe Teams Aufgaben, die traditionell bei zentralen Data-Engineering- oder BI-Teams lagen:
- Bereitstellung wiederverwendbarer, produktionsreifer Data Products, die sich in unternehmensweite Plattformen integrieren
- Sicherstellung von SLAs, CI/CD-Prozessen (Versionierung, Change Management) und nachvollziehbaren Audit-Trails
- Umsetzung granularer Sicherheitsmaßnahmen und Zugriffskontrollen zur Einhaltung interner Richtlinien und gesetzlicher Anforderungen
- Erstellung und Pflege vollständiger Dokumentation und Lineage (Nachvollziehbarkeit) aller Datenobjekte
- Deployment, Testing und Promotion von Pipelines und semantischen Modellen über Entwicklungs-, Test- und Produktivumgebungen hinweg
Diese Aufgaben erfordern nicht nur technische Fähigkeiten, sondern auch Kenntnisse in DevOps, Data Governance und Plattformarchitektur. Das Problem: Die meisten Fachbereichs-Teams bestehen aus Business-Analysten, Fachbereichsverantwortlichen, Finanzexperten, Marketing- oder Supply-Chain-Profis – also Menschen, die die Bedeutung der Daten verstehen, aber nicht deren technische Operationalisierung.

Warum Excel und SQL nicht ausreichen
Fehlen geeignete Tools und Automatisierung, greifen Domänenteams zu dem, was sie kennen – oft weit über den ursprünglichen Einsatzzweck hinaus:
- Geschäftskritische Reports in Excel werden zu Single Points of Failure, mit Versionschaos und instabilen Makros
- Ad-hoc-SQL-Abfragen in Notebooks oder Power BI lassen sich nicht reproduzieren und entfernen sich von zentralen semantischen Schichten
- Power-BI-Workspaces entwickeln sich unabhängig voneinander, mit unterschiedlichen Berechnungen und KPIs – was zu Widersprüchen zwischen Abteilungen führt
- Schemaänderungen in Quellsystemen zerstören manuell gepflegte Pipelines und verursachen Backlogs an manuellen Korrekturen
Was als schnelle Lösung beginnt, endet oft als technisches Schuldenpaket. Anstatt Geschwindigkeit zu bringen, produziert Fachbereich-Autonomie (Domänenautonomie) parallele BI-Universen mit hohem Risiko. Ohne Engineering-Prozesse und Automatisierung wird Data Mesh zur operativen Belastung.
Was Fachbereichs-Teams wirklich brauchen
Damit Data Mesh funktioniert, müssen Domänenteams vertrauenswürdige, regelkonforme Data Products liefern können – ohne Full-Stack-Engineers zu werden. In einem echten Data-Mesh-Modell sollten Data Products:
- Auffindbar sein – leicht zu finden und für andere Teams verständlich
- Adressierbar sein – eindeutig identifizierbar über alle Domänen hinweg
- Interoperabel sein – im Einklang mit gemeinsamen Standards für Modellierung, KPIs und Datenqualität
- Sicher und von Beginn an governed sein – mit eingebauten Regeln zu Zugriff, Datenschutz und Compliance
Dafür brauchen Fachbereiche nicht nur Datenzugriff, sondern die Fähigkeit, Data Products selbstständig und sicher aufzubauen:
- Wiederverwendbare Blueprints für Datenaufnahme, Datenmodellierung, Historisierung (Slowly Changing Dimensions & Snapshots) und Zugriffskontrollen gemäß Unternehmensstandards
- Automatisierte Deployment-Pipelines, die Umgebungswechsel (Dev/Test/Prod) unterstützen und menschliche Fehler minimieren
- Eingebaute Governance durch metadatenbasierte Namenskonventionen, Klassifikationen und Compliance-Policies
- Automatisch generierte Lineage und Dokumentation, die Datenflüsse vom Ursprung bis zum Dashboard ohne manuellen Aufwand nachvollziehbar machen
- Low-Code- oder No-Code-Oberflächen, die es erlauben, mit fachlichen Begriffen zu modellieren – statt mit SQL oder Skriptlogik
Domänenteams brauchen nicht mehr Tools – sie brauchen geführte, wiederverwendbare Bausteine, die Komplexität abstrahieren und unternehmensweite Konsistenz sicherstellen.
Metadatenautomatisierung: Die Last reduzieren
Metadatenbasierte Automatisierung hilft, Datenstandards und Richtlinien konsistent über alle Fachbereiche hinweg umzusetzen. Anstatt Custom-Logik in Silos zu bauen, stellen Plattformteams wiederverwendbare Templates und Delivery-Muster bereit. So entsteht Effizienz, ohne die Eigenverantwortung der Fachbereiche zu beschneiden.
Vorteile für Fachbereichs-Teams:
- Geführte Modellierungserfahrung, die Architekturprinzipien, Namenskonventionen und Qualitätsregeln direkt in den Workflow einbettet
- Automatisierte Pipeline-Erstellung für Aufnahme, Transformation und semantische Schicht – ob mit ADF, Synapse oder Fabric Pipelines
- Dynamische Lineage- und Compliance-Kontrolle, inklusive Pseudonymisierung, Maskierung und DSGVO-Nachverfolgung
- Integrierte Versionierung und Rollbacks, um Änderungen über Umgebungen hinweg sicher zu steuern
- No-Code-Orchestrierung, sodass kein Skript oder YAML-Code für den operativen Betrieb nötig ist
Automatisierung wird damit zum Sicherheitsnetz, das verteilte Verantwortung ermöglicht – ohne Chaos.
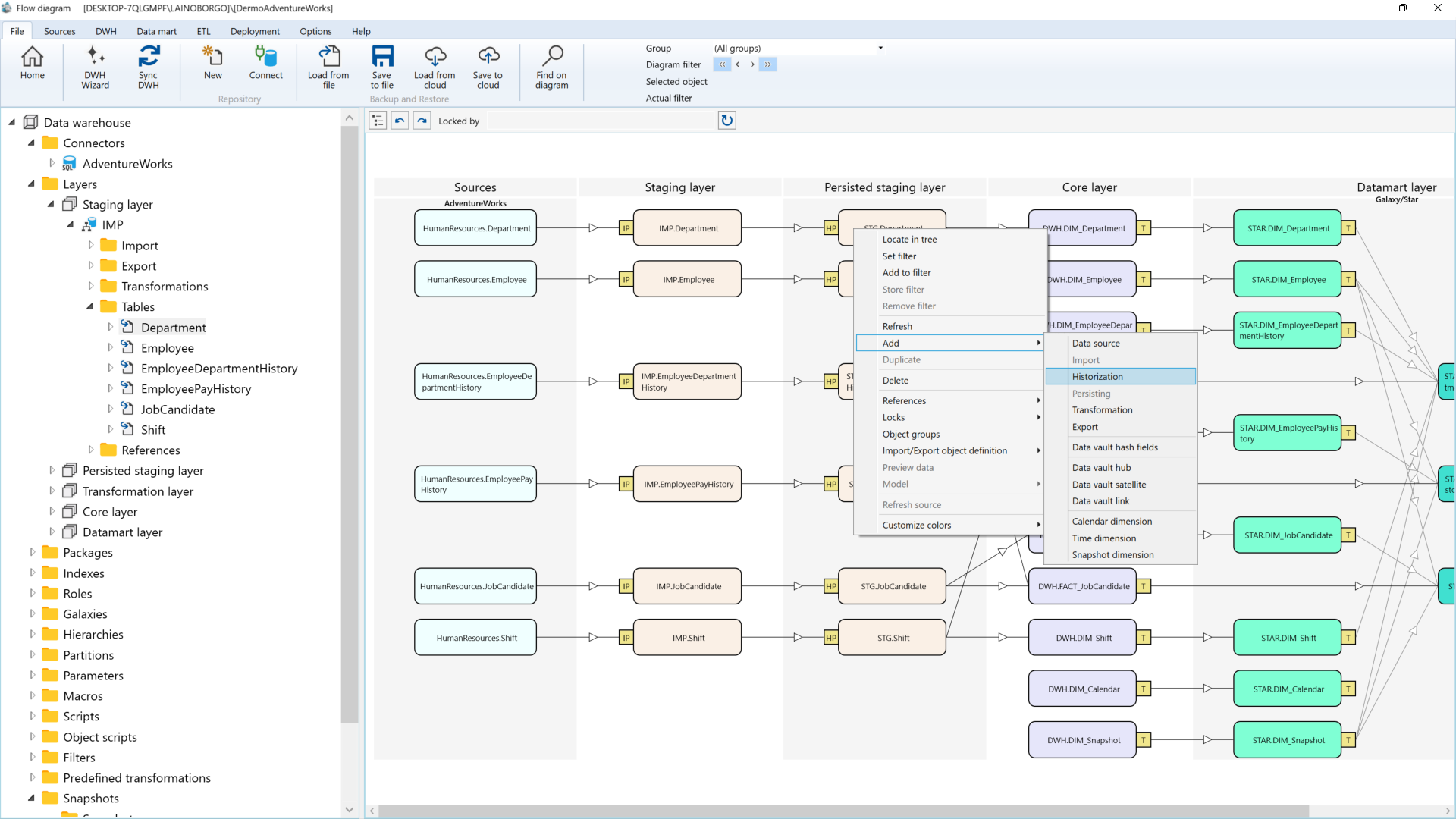
Wie AnalyticsCreator die Lücke schließt
AnalyticsCreator wurde speziell entwickelt, um Fachbereichs-Teams die Möglichkeit zu geben Ihre Datenmodelle selbst zu verwalten und anderen Fachabteilungen zur Verfügung zu stellen. Statt ein weiteres Tool einzuführen, etabliert es eine strukturierte, metadatengetriebene Grundlage, die sich über Domänen und Plattformen skalieren lässt.
- Visuelle Metadatenmodellierung für Fachbereiche und Architekten
- Automatische Generierung von SQL-Modellen, ADF-/Fabric-Pipelines und semantischen Schichten
- Lineage und Dokumentation werden zur Laufzeit erzeugt
- DSGVO-Konformität inkl. Pseudonymisierung und Zugriffskontrolle
- CI/CD-Integration für DevOps-fähige Deployments
Im Unterschied zu klassischen Low-Code-ETL-Tools vereinfacht AnalyticsCreator nicht nur die Entwicklung – es erzwingt architektonische Integrität. Fachbereiche nutzen wiederverwendbare Muster, Plattformteams behalten zentrale Kontrolle, und Enterprise-Architekten erhalten vollständige Traceability von der Quelle bis zum Power-BI-Dashboard.
Für Fachbereichs-Teams bedeutet das:
- Fokus auf fachliche Inhalte statt Syntax
- Nutzung genehmigter Modellierungs-Patterns
- Vertrauen in die Einhaltung von Security & Governance
- Schneller Aufbau produktionsreifer Data Products
Fazit
Fachbereichsautonomie bedeutet weder maximale Komplexität noch höhere Risiken. Wenn Domänenteams Data Products verantworten sollen, brauchen sie Tools, die sie von unnötiger technischer Last entlasten.
Mit metadatengesteuerter Automatisierung und einer Plattform wie AnalyticsCreator wird Data Mesh skalierbar – ohne Governance-Verlust oder unrealistische Anforderungen an die Fachbereiche.
Vereinbaren Sie ein Gespräch mit uns – wir zeigen Ihnen, wie Sie mit fachbereichsgesteuerter Automatisierung auf Ihrer Microsoft-Datenplattform starten können.