Kimball Modeling in Microsoft Fabric SQL: Automated with AnalyticsCreator


Microsoft Fabric SQL provides a scalable warehouse engine, but not the modeling logic. AnalyticsCreator fills the gap by automating Kimball-based warehouse creation, ADF pipeline generation, and Delta integration using metadata—fully governed and ready for lakehouse consumption.
Why AnalyticsCreator for Fabric SQL?
Fabric SQL enables scalable structured storage, but building a governed, dimensional warehouse manually still requires modeling skills, custom ETL, and orchestration. AnalyticsCreator removes this complexity. It turns metadata-defined models into complete Fabric SQL deployments, with pipelines and lakehouse compatibility built in.
Step-by-step: How AnalyticsCreator works with Fabric SQL
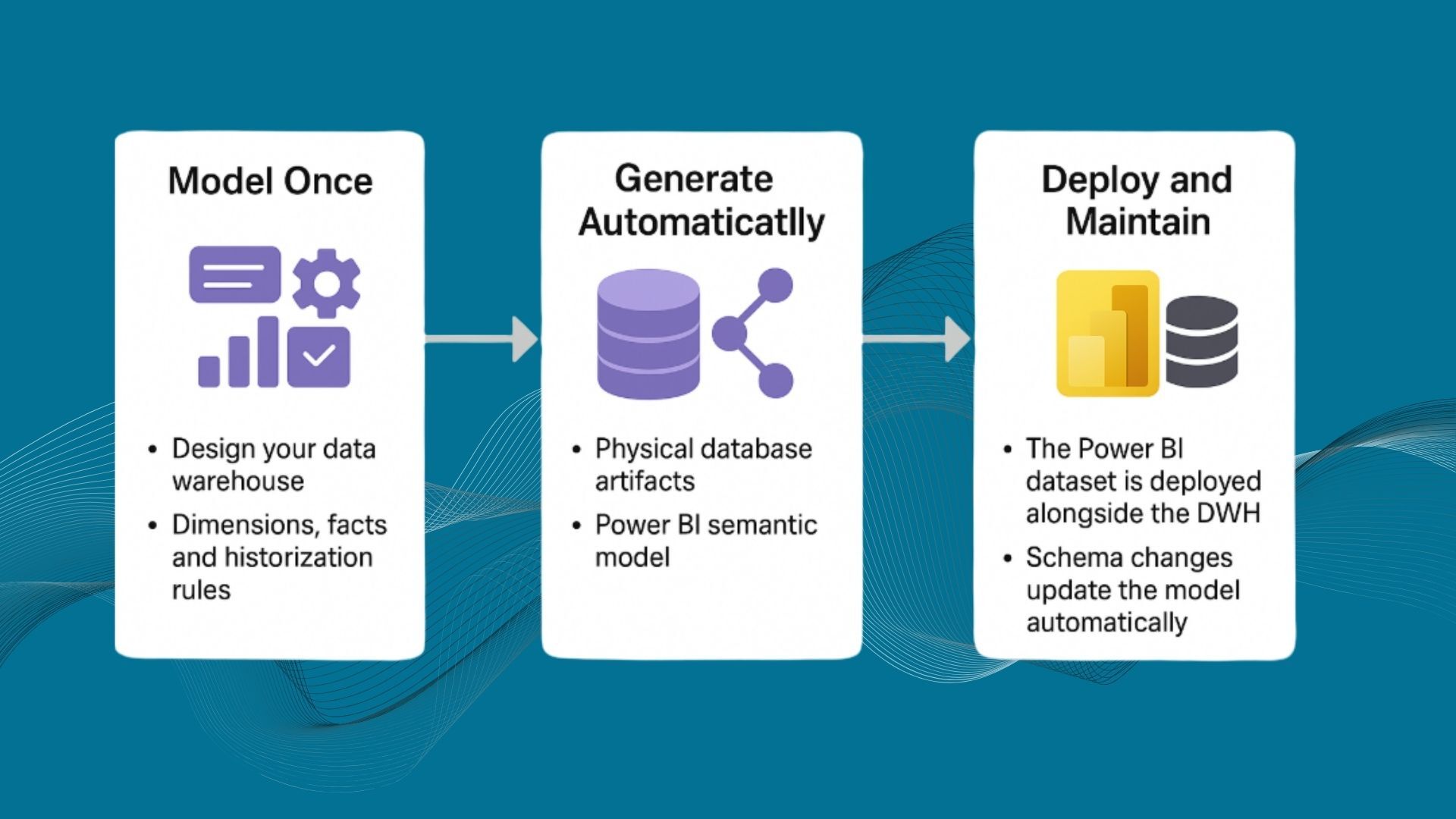
Step 1: Model your warehouse using Kimball
Using the built-in visual studio, define facts, dimensions, hierarchies, and SCD logic. The metadata model drives consistency, governance, and automation across the entire lifecycle.
Step 2: Deploy to Fabric SQL
With one click, AnalyticsCreator generates a DACPAC and deploys it into Fabric SQL. It creates a layered architecture:
- IMP: Raw ingestion layer
- STG: Initial data transformations
- TRN: Cleaned, persisted staging
- DWH: Curated dimensional data warehouse
- STAR: Semantic layer for BI and self-service
Step 3: Generate ADF pipelines automatically
AnalyticsCreator builds metadata-driven ADF pipelines that:
- Support full and incremental loads
- Include SCD logic, auditing, and error handling
- Use parameterized configurations across environments
- Run end-to-end without manual coding
Step 4: Surface data as OneLake Delta tables
All tables deployed to Fabric SQL are automatically available as Delta tables in OneLake. Power BI connects via Direct Lake, Spark notebooks query the same datasets, and users benefit from a unified analytics layer.
Key benefits of using AnalyticsCreator with Microsoft Fabric
| Feature | Value |
|---|---|
| Metadata-driven modeling | Improves consistency and reduces rework |
| Fabric SQL automation | Delivers governed, layered architecture with no manual coding |
| Reusable ADF pipelines | Accelerates ingestion and SCD tracking |
| CI/CD and audit compliance | Supports Git workflows, parameterized deployments, and traceability |
| Delta integration | Makes data available for BI, Spark, and AI workloads |
Final takeaway
AnalyticsCreator brings traditional Kimball modeling into the Fabric era. With metadata as the driver, you automate warehouse design, deployment, ingestion, and consumption—without compromise. It’s the fastest, most governable way to build modern SQL warehouses for the Microsoft cloud.
Frequently Asked Questions
Does Microsoft Fabric support Kimball modeling natively?
No, Fabric provides the engine and storage but not warehouse modeling or orchestration logic.
What does AnalyticsCreator automate in Fabric SQL?
It automates table modeling, DACPAC deployment, ADF pipelines, and Delta exposure in OneLake.
How are pipelines generated?
Pipelines are created automatically based on metadata, including load types, SCD logic, and auditing.
Can I use Direct Lake mode with these deployments?
Yes. Tables deployed via AnalyticsCreator are surfaced as Delta tables, fully compatible with Power BI Direct Lake.
What modeling methodology does AnalyticsCreator support?
It supports Kimball star schema modeling, including Type 1 and Type 2 SCDs, conformed dimensions, and semantic layers.
How is CI/CD handled?
AnalyticsCreator integrates with Azure DevOps or GitHub and uses metadata for automated, version-controlled deployments.
Is this only for Fabric or also for SQL Server?
Both. The same metadata can deploy to SQL Server, Azure SQL, or Fabric SQL environments.
What’s the main benefit of using AnalyticsCreator for Fabric?
Faster delivery of governed, dimensional data warehouses which are ready for BI, Spark, and AI without writing code.