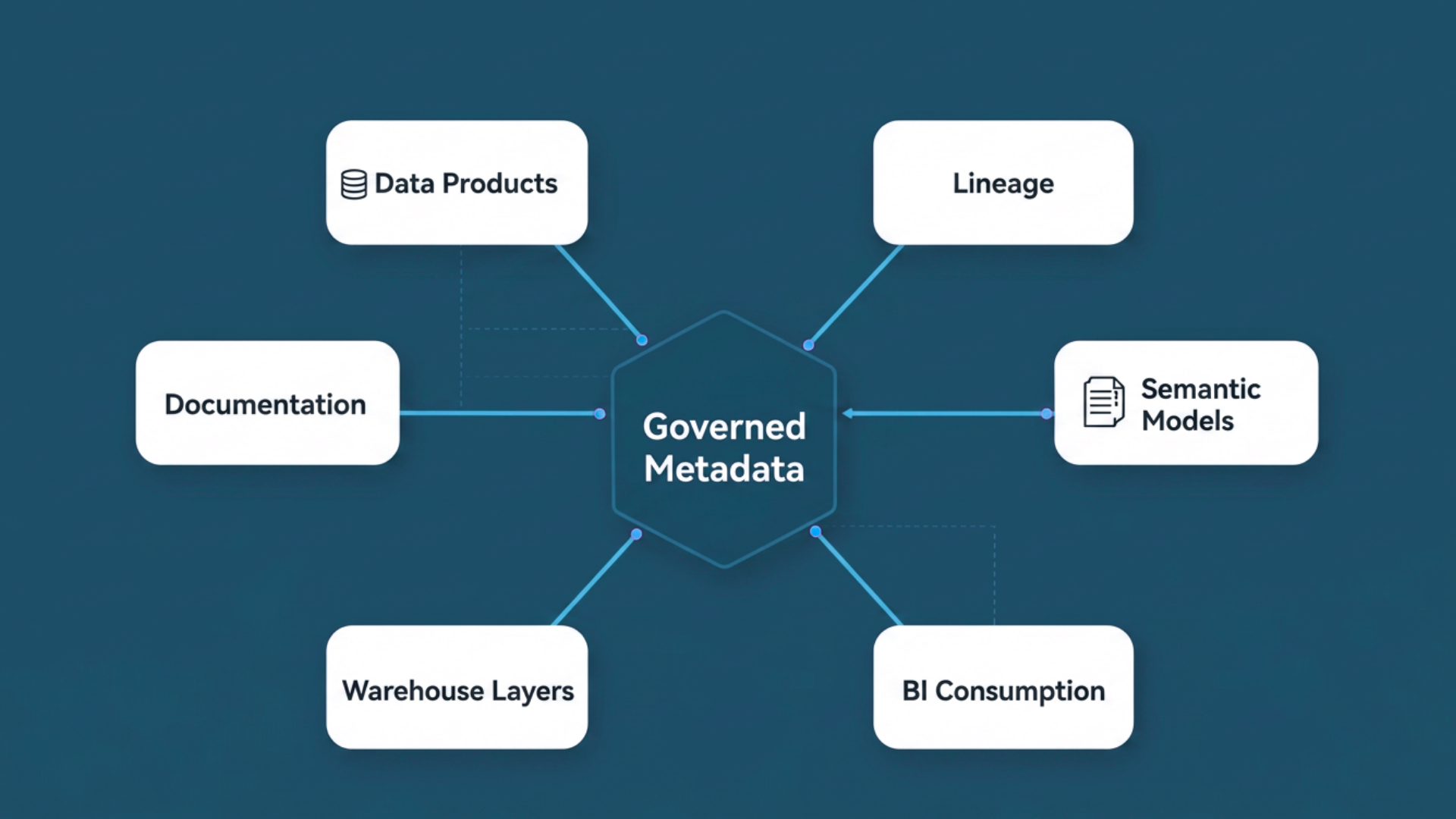
Data Mesh promises to decentralize data ownership by empowering business domain teams to deliver their own data products. It sounds great in theory: faster delivery, better relevance, and improved ownership. Although designed to simplify work and improve collaboration, many organizations become overwhelmed—leading to increased stress, friction between teams, and frustration.
Domain teams are suddenly expected to act like engineers—handling data pipelines, documentation, security, governance, CI/CD, and quality management—on top of their actual business responsibilities. Most teams are not equipped for this, and the cognitive load slows progress, breaks trust in the model, and creates the perception that they are lagging behind.
This article explains how to make Data Mesh operational by giving domain teams the automation, patterns, and guardrails they need—turning them into citizen developers rather than accidental engineers. Without this support, Data Mesh often results in inconsistent delivery, shadow IT, and serious governance gaps.
What Domain Teams Are Being Asked to Do
In most Data Mesh implementations, domain-aligned teams are assigned responsibilities traditionally carried out by centralized data engineering or BI teams:
- Deliver reusable, production-grade data products that integrate with enterprise platforms
- Ensure SLAs, CI/CD processes, versioning, and audit trails are in place
- Apply granular security and access control aligned with organizational policies
- Produce and maintain end-to-end documentation and lineage
- Deploy, test, and promote pipelines and models across dev, test, and production environments
The problem? These teams consist of business experts—analysts, finance managers, marketers, supply chain specialists—not engineers. They understand the business meaning of data, but not how to operationalize it at scale.

Why Excel and SQL Aren’t Enough
When domain teams lack specialized tooling and automation, they fall back on familiar tools—often stretching them far beyond their intended use:
- Business-critical reports built in Excel become single points of failure, with versioning chaos and fragile macros
- Ad hoc SQL queries in notebooks or Power BI lack repeatability and drift from governed semantic layers
- Power BI workspaces diverge in logic, calculations, and metric definitions, leading to KPI inconsistency across departments
- Schema changes in source systems break manual pipelines, triggering a backlog of reactive fixes
What starts as a quick win turns into long-term technical debt. Domain autonomy, instead of accelerating delivery, creates parallel BI universes and hidden risks. Without engineering-grade processes and automation, Data Mesh quickly becomes an operational liability.
What Domain Teams Actually Need
To succeed with Data Mesh, domain teams must be able to deliver trusted, governed data products—without becoming full-stack engineers. Proper data products should be:
- Discoverable – easy for others to find and interpret
- Addressable – uniquely identifiable across domains
- Interoperable – aligned with shared standards, KPIs, and quality rules
- Secure and governed – compliant by design with enterprise policies
To achieve this, domain teams need more than access—they need the means to build with confidence:
- Reusable blueprints for ingestion logic, modeling, historization (SCDs and snapshots), and access policies
- Push-button deployment pipelines to automate promotion and eliminate deployment errors
- Embedded governance through metadata-enforced standards
- Auto-generated lineage and documentation for full traceability
- Low-code or no-code modeling interfaces so teams can work in business terms—not SQL
Domain teams don’t need more tools—they need guided, composable building blocks that abstract complexity while enforcing enterprise standards.
Metadata Automation: Reducing the Burden
Metadata automation streamlines how standards and policies are applied across domains. Instead of reinventing logic in silos, platform teams can deliver reusable templates and governed delivery patterns.
This provides domain teams with:
- Guided experiences that encode architectural patterns and quality rules directly into workflows
- Automated pipeline generation for ingestion, transformation, and semantic layers
- Built-in lineage and compliance enforcement including masking, pseudonymization, and GDPR tagging
- Integrated versioning and rollback for controlled change management
- No-code orchestration to remove the need for scripts or deployment YAML
Automation becomes the safety net that allows distributed teams to build without chaos.
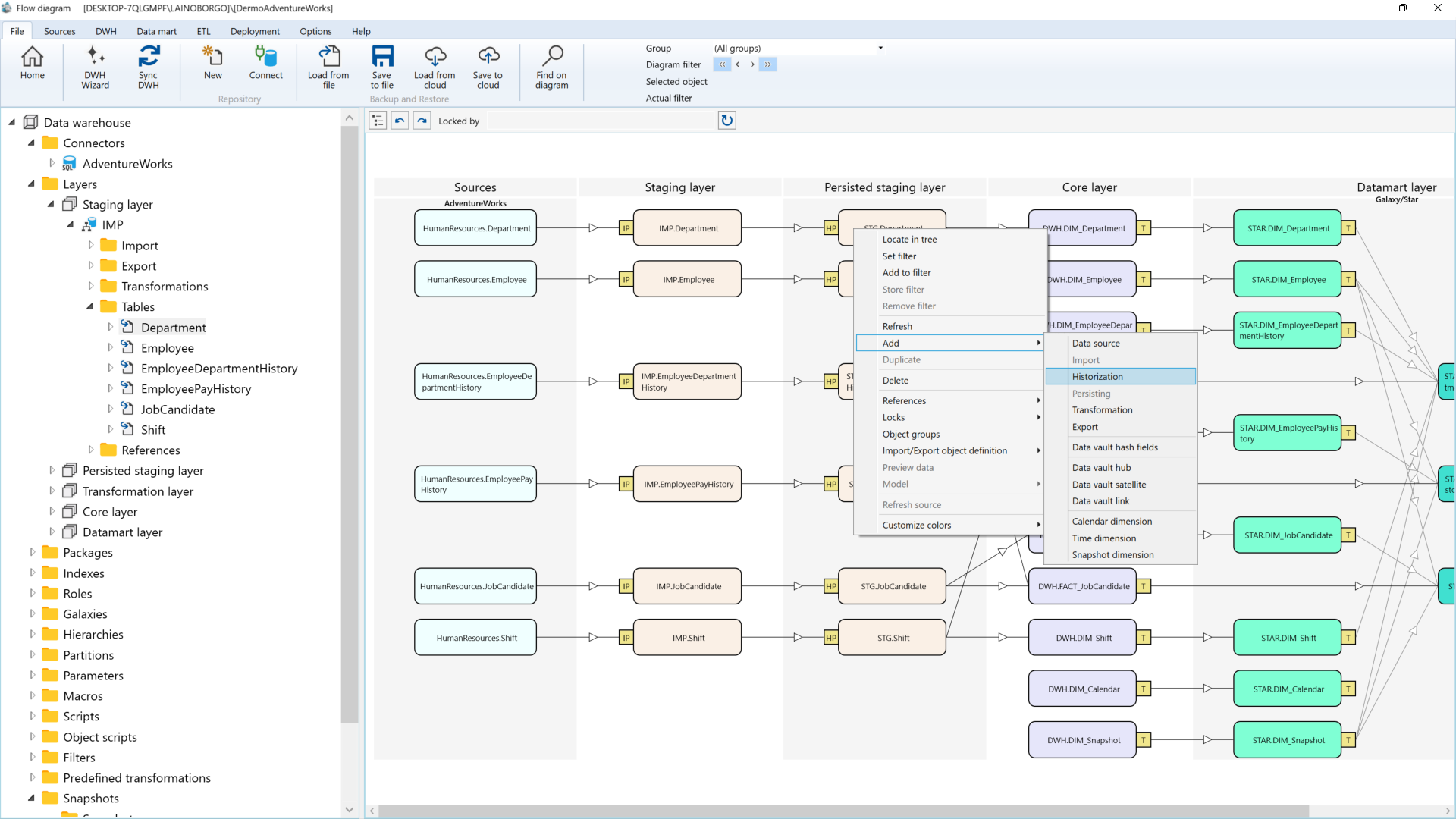
How AnalyticsCreator Bridges the Gap
AnalyticsCreator was specifically designed to enable departmental teams to manage their data models themselves and make them available to other departments. Rather than adding another tool, it introduces a structured, metadata-driven foundation that scales across domains and data platforms.
- Visual metadata modelling for domains and architects
- Automated generation of SQL models, ADF/Fabric pipelines, and semantic layers
- Built-in lineage and documentation, generated at runtime
- GDPR compliance, including pseudonymization and access control modeling
- DevOps-ready delivery through CI/CD pipeline integration
Unlike traditional low-code platforms, AnalyticsCreator enforces architectural integrity. Domain teams inherit approved building blocks, platform teams maintain oversight, and architects get full traceability from source to Power BI.
For domain teams, this means they can:
- Focus on business meaning, not syntax
- Use approved modeling patterns
- Rely on built-in security and compliance
- Deliver production-grade data products quickly
Conclusion
Domain autonomy should not mean domain complexity. For Data Mesh to work, domain teams need tools that shield them from unnecessary engineering.
With metadata-driven automation and platforms like AnalyticsCreator, organizations can scale domain delivery without sacrificing governance or placing unrealistic burdens on business teams.
Ready to operationalize Data Mesh without overwhelming your domain teams?
Let’s show you how metadata-driven automation can unlock scalable delivery across your Microsoft data platform.