Effizientes Datenmanagement ist entscheidend für Unternehmen, um wettbewerbsfähig zu bleiben. Automatisierte Datenpipelines straffen Abläufe, reduzieren Fehler und liefern schneller wertvolle Einblicke für operative und strategische Entscheidungen.
Verständnis automatisierter Datenpipelines
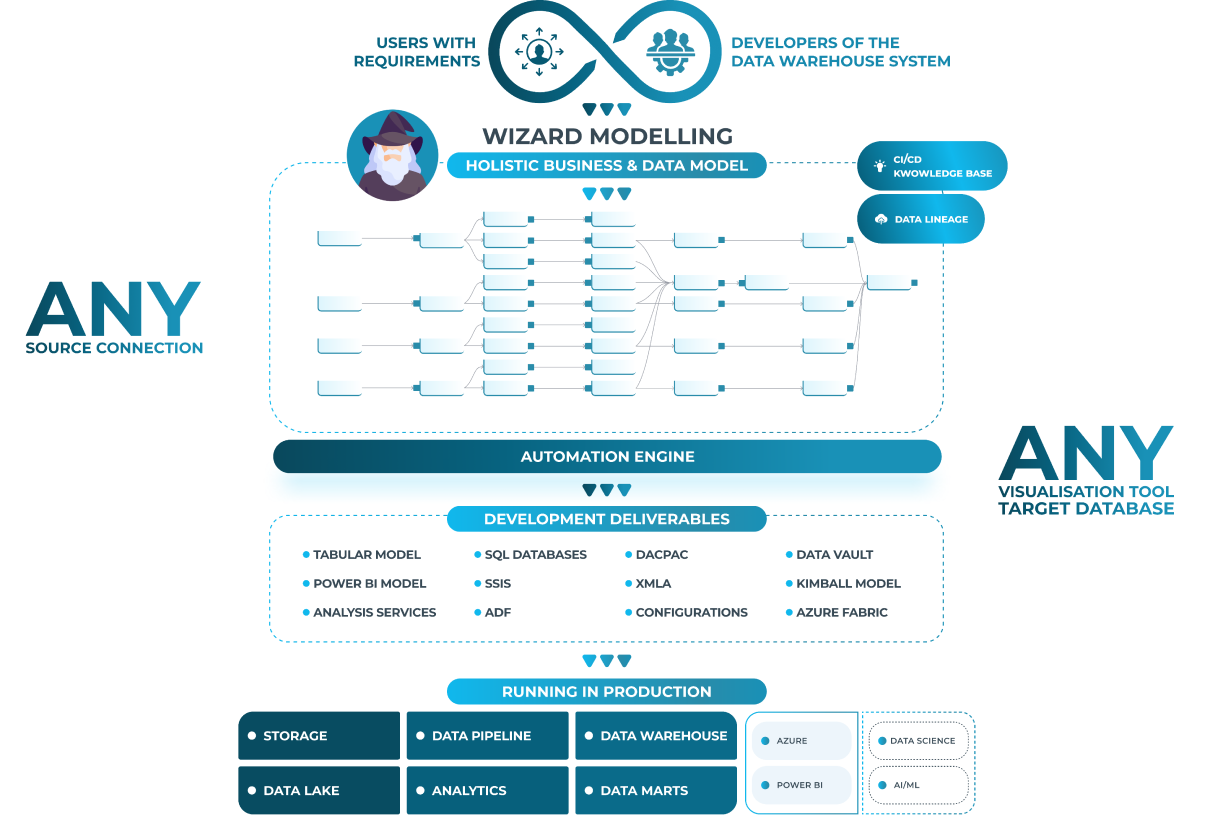
Eine automatisierte Datenpipeline ist eine Reihe verbundener Komponenten, die zusammenarbeiten, um Daten zu erfassen, zu verarbeiten, zu speichern und zu visualisieren. Sie funktioniert wie ein „Förderband für Daten“ und stellt einen reibungslosen, wiederholbaren und effizienten Fluss von der Quelle bis zum Ziel sicher.
Wichtige Komponenten
- Datenaufnahme: Extraktion von Daten aus verschiedenen Quellen wie Datenbanken, APIs, Dateien, SaaS-Anwendungen und Streaming-Plattformen.
- Datenverarbeitung: Transformation, Bereinigung, Anreicherung und Harmonisierung der Daten, um sie für Analyse und Reporting nutzbar zu machen.
- Datenspeicherung: Ablage der verarbeiteten Daten in geeigneten Zielspeichern wie Data Warehouses, Data Marts oder Data Lakes.
- Datenvisualisierung: Erstellung von Reports, Visualisierungen und Dashboards, um Erkenntnisse verständlich und zielgruppengerecht darzustellen.
Arten von Datenpipelines
- Batch-Pipelines: Verarbeiten Daten in fest definierten Intervallen in Batches, beispielsweise stündlich oder täglich.
- Echtzeit-Pipelines: Verarbeiten Daten nahezu in Echtzeit, sobald sie erzeugt werden, und liefern sofortige Einblicke.
- Hybride Pipelines: Kombinieren Batch- und Echtzeit-Verarbeitung, um unterschiedliche Anforderungen von Fachbereichen optimal zu unterstützen.
Vorteile automatisierter Datenpipelines
- Effizienz: Automatisierung reduziert manuelle Eingriffe, minimiert Fehler und spart Zeit.
- Skalierbarkeit: Gut konzipierte Pipelines können wachsende Datenmengen bewältigen, ohne die Performance zu beeinträchtigen.
- Konsistenz: Standardisierte, automatisierte Prozesse gewährleisten einheitliche Datenqualität und hohe Zuverlässigkeit.
- Kosteneffizienz: Reduzierte Betriebs- und Personalkosten durch Automatisierung und bessere Nutzung vorhandener Daten.
Wichtige Technologien und Werkzeuge
- ETL-/ELT-Tools: Talend, Informatica, SSIS oder Fivetran unterstützen Extraktion, Transformation und Laden von Daten.
- Datenintegrationsplattformen: Orchestrierungs- und Workflow-Engines wie Apache Airflow, AWS Glue oder Azure Data Factory.
- Cloud-Dienste: Hyperscaler wie AWS, Azure und Google Cloud bieten verwaltete Datenpipeline-Services, inkl. Monitoring, Skalierung und Security-Features.
- Open-Source-Lösungen: Apache Kafka, Apache NiFi, Apache Spark und weitere Frameworks für Streaming, Verarbeitung und Integration.
Implementierungsstrategien
- Planung: Definieren Sie klare Ziele, identifizieren Sie Datenquellen und -ziele und wählen Sie passende Werkzeuge und Plattformen.
- Design: Entwerfen Sie eine robuste Pipeline-Architektur unter Berücksichtigung von Datenvolumen, -geschwindigkeit, Latenzanforderungen und Komplexität.
- Bereitstellung: Implementieren Sie die Pipeline, automatisieren Sie Deployments und stellen Sie eine saubere Konfiguration, Testung und Dokumentation sicher.
- Überwachung und Wartung: Überwachen Sie die Pipeline kontinuierlich, beheben Sie Probleme proaktiv und passen Sie die Lösung laufend an neue Anforderungen an.
Automatisierte Datenpipelines mit AnalyticsCreator
AnalyticsCreator bietet eine umfassende Plattform für den Aufbau und Betrieb automatisierter Datenpipelines – von der Modellierung bis zur Bereitstellung für BI-Frontends.
- Push-Konzept: Automatische Erstellung von Daten- und Analysemodellen für Frontends wie Power BI, Tableau und Qlik.
- Pull-Konzept: Anbindung an unterschiedliche BI-Frontends, um maßgeschneiderte, semantische Schichten und Datensichten zu liefern.
- Datenschutz & Sicherheit: Fokus auf Datenschutz, Rollen- und Rechtekonzepte sowie revisionssichere Datenverarbeitung.
- Lernressourcen: Umfangreiche Tutorials, Dokumentation und Community-Support unterstützen Teams beim Einstieg und bei der Professionalisierung.

Herausforderungen und Lösungen
- Häufige Herausforderungen: Unzureichende Datenqualität, heterogene und komplexe Datenquellen sowie technische Integrationshürden.
- Lösungen: Konsequent angewandte Datenbereinigung, gezielter Einsatz von Datenintegrations- und Orchestrierungstools sowie Einbindung von Fachexperten und Data-Engineering-Know-how.
Automatisierte Datenpipelines sind ein zentrales Element, um im Zeitalter von Big Data und Self-Service-Analytics erfolgreich zu sein. Durch die Straffung von Datenmanagementprozessen, die Steigerung der Effizienz und die schnellere Bereitstellung hochwertiger Daten schaffen Unternehmen die Basis für fundierte, datengetriebene Entscheidungen. AnalyticsCreator stellt dafür eine leistungsstarke Plattform bereit, um automatisierte Datenpipelines effektiv zu erstellen und zu verwalten.