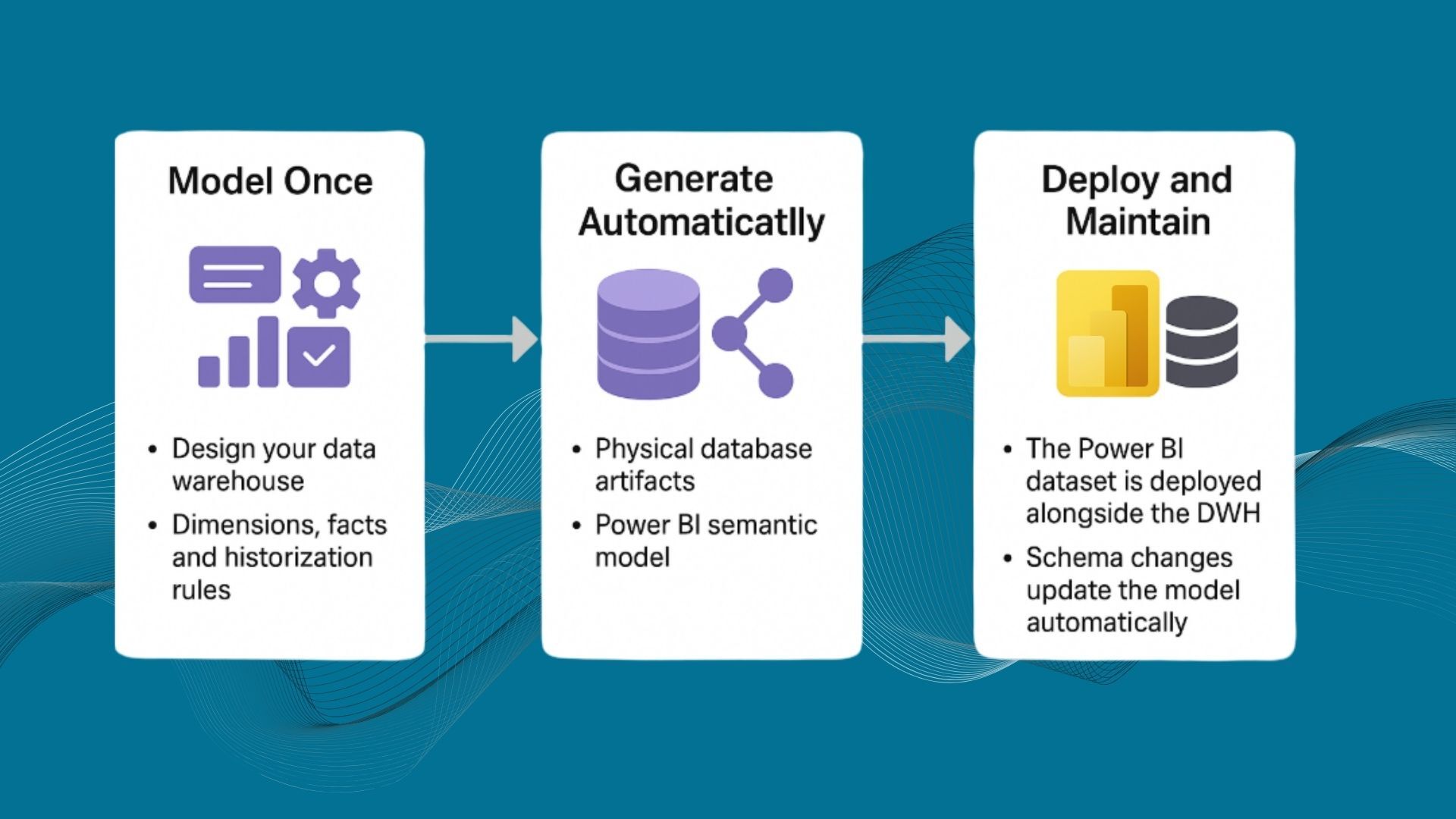
Die Datenmodellierung ist ein kritischer Schritt bei der Planung und Entwicklung eines Data Warehouse. Sie umfasst die Erstellung einer konzeptionellen und logischen Darstellung der Daten, die im Data Warehouse gespeichert werden. Diese Darstellung hilft sicherzustellen, dass die Daten im Warehouse korrekt, konsistent und gut strukturiert sind.
Es gibt verschiedene Datenmodellierungstechniken, die im Kontext der Datenspeicherung verwendet werden können. Die vier am häufigsten verwendeten Techniken sind die Inmon-Methode, die Kimball-Methode, die Anchor-Modellierung und die Data-Vault-Modellierung. Hier ist eine kurze Übersicht über jede Technik:
-
Inmon-Methode: Die Inmon-Methode, benannt nach ihrem Erfinder Bill Inmon, ist ein Top-down-Ansatz für die Datenmodellierung. Diese Methode betont die Bedeutung der Erstellung eines einzigen, integrierten Datenmodells, das in der gesamten Organisation verwendet wird. Inmons Ansatz besteht darin, ein großes, zentralisiertes Data Warehouse zu erstellen, das alle Daten der Organisation enthält, die dann in Data Marts für bestimmte Geschäftsprozesse transformiert und geladen werden können.
-
Kimball-Methode: Die Kimball-Methode, entwickelt von Ralph Kimball, ist ein Ansatz zur Datenmodellierung, der auch top-down angewendet werden kann. Ursprünglich für ihren Bottom-up-Ansatz bekannt, hebt die Kimball-Methode die Bedeutung des Aufbaus von Data Marts mit Schwerpunkt auf spezifische Fachbereiche oder Geschäftsprozesse hervor. In dieser Methode werden Daten denormalisiert, um die Abfrageleistung zu verbessern, und das Datenmodell wird auf der Grundlage von Geschäftsprozessen mit Fakt-Tabellen und zugehörigen Dimensionstabellen entworfen. Im Laufe der Zeit haben Berater die Kimball-Methode auch mit einem Top-down-Ansatz verwendet und ihre Prinzipien an unterschiedliche Projektanforderungen angepasst.
-
Anchor-Modellierung: Die Anchor-Modellierung ist eine relativ neue Datenmodellierungstechnik, die die Modellierung von Daten in Bezug auf „Ankerpunkte“ betont. Ein Ankerpunkt repräsentiert einen grundlegenden Begriff oder eine Entität in der Organisation, und die Daten werden um diese Ankerpunkte modelliert. Die Technik ermöglicht hohe Flexibilität beim Hinzufügen oder Ändern von Ankerpunkten und zugehörigen Attributen und lässt sich dadurch gut an sich ändernde Geschäftsanforderungen anpassen.
-
Data-Vault-Modellierung: Die Data-Vault-Modellierung basiert auf dem Konzept einer „Hub-and-Spoke“-Architektur. In einem Data-Vault-Modell werden die Daten in drei Haupttypen von Tabellen organisiert: Hub-Tabellen, Link-Tabellen und Satelliten-Tabellen. Die Hub-Tabellen repräsentieren die Kernentitäten der Organisation, während die Link-Tabellen die Beziehungen zwischen diesen Entitäten darstellen. Die Satelliten-Tabellen enthalten beschreibende und historisierte Informationen zu den Entitäten und ihren Beziehungen.
Jede dieser Datenmodellierungstechniken hat ihre eigenen Vor- und Nachteile, und die Wahl der richtigen Technik hängt von den spezifischen Anforderungen der Organisation ab.
Datengenauigkeit sicherstellen
 Die Datenmodellierung stellt sicher, dass die im Data Warehouse gespeicherten Daten korrekt und vollständig sind. Dies wird erreicht, indem relevante Datenquellen identifiziert, geeignete Datenelemente ausgewählt und Beziehungen zwischen den Datenelementen sauber modelliert werden.
Die Datenmodellierung stellt sicher, dass die im Data Warehouse gespeicherten Daten korrekt und vollständig sind. Dies wird erreicht, indem relevante Datenquellen identifiziert, geeignete Datenelemente ausgewählt und Beziehungen zwischen den Datenelementen sauber modelliert werden.
Die Gewährleistung der Datengenauigkeit ist ein kritischer Bestandteil des Datenmanagements. Einige Schritte, die Sie unternehmen können, um sicherzustellen, dass Ihre Daten korrekt sind:
- Relevante Datenquellen identifizieren: Verstehen Sie, welche Daten Sie benötigen, wo sie liegen und wie sie abgerufen werden können.
- Datenqualitätsregeln festlegen: Definieren Sie klare Regeln für Vollständigkeit, Konsistenz, Genauigkeit und Gültigkeit, abgestimmt auf Ihre Geschäftsanforderungen.
- Datenvalidierungschecks implementieren: Nutzen Sie automatische Prüfungen wie Datenprofiling, Datenbereinigung und Datenstandardisierung, um die Einhaltung der Qualitätsregeln sicherzustellen.
- Datenqualität überwachen: Überprüfen Sie Ihre Daten regelmäßig und etablieren Sie Datengovernance-Prozesse, um Qualitätsstandards dauerhaft sicherzustellen.
- Stakeholder einbinden: Beziehen Sie Dateneigentümer, Datenstewards und Endanwender in den Prozess ein, damit alle Verantwortung und Nutzen der Datengenauigkeit verstehen.
- Daten regelmäßig aktualisieren und pflegen: Stellen Sie durch Updates und Synchronisationen sicher, dass die Daten über alle Systeme hinweg aktuell bleiben.
Verbesserung der Datenkonsistenz
 Die Datenmodellierung trägt zur Verbesserung der Datenkonsistenz bei, indem ein standardisiertes Datenmodell erstellt wird, das im gesamten Unternehmen verwendet wird. Diese Konsistenz stellt sicher, dass alle Mitarbeiter dieselbe Terminologie und dieselben Datendefinitionen verwenden, was das Fehlerrisiko reduziert und die Datenqualität erhöht.
Die Datenmodellierung trägt zur Verbesserung der Datenkonsistenz bei, indem ein standardisiertes Datenmodell erstellt wird, das im gesamten Unternehmen verwendet wird. Diese Konsistenz stellt sicher, dass alle Mitarbeiter dieselbe Terminologie und dieselben Datendefinitionen verwenden, was das Fehlerrisiko reduziert und die Datenqualität erhöht.
Um Datenkonsistenz nachhaltig zu sichern, können Sie folgende Maßnahmen ergreifen:
- Datenstandards definieren: Entwickeln Sie Standards, wie Daten erfasst, gespeichert und verwendet werden sollen. Diese sollten auf Branchen-Best-Practices basieren und klar kommuniziert werden.
- Daten-Governance etablieren: Implementieren Sie ein Governance-Framework mit Richtlinien, Prozessen und klaren Rollen (Dateneigentümer, Datenstewards etc.).
- Datenvalidierungsprüfungen implementieren: Integrieren Sie automatisierte Prüfungen wie Datenprofiling, Bereinigung und Standardisierung in Ihre Prozesse.
- Datenqualität regelmäßig überwachen: Führen Sie laufende Kontrollen, Stichproben und Audits durch, um die Einhaltung der Standards sicherzustellen.
- Schulungen und Unterstützung anbieten: Sensibilisieren Sie Fachbereiche für die Bedeutung von Datenkonsistenz und zeigen Sie, wie Standards praktisch umgesetzt werden.
- Master Data Management (MDM) nutzen: Implementieren Sie MDM, um eine zentrale, autoritative Quelle für Schlüsselobjekte (z. B. Kunden, Produkte, Lieferanten) zu schaffen.
Datenintegration erleichtern
 Die Datenmodellierung erleichtert die Datenintegration, indem Beziehungen zwischen verschiedenen Datenquellen identifiziert und ein gemeinsames Datenmodell geschaffen wird, das im gesamten Unternehmen genutzt werden kann. Dies verringert redundante Datenspeicherung und verbessert Genauigkeit und Konsistenz der Daten.
Die Datenmodellierung erleichtert die Datenintegration, indem Beziehungen zwischen verschiedenen Datenquellen identifiziert und ein gemeinsames Datenmodell geschaffen wird, das im gesamten Unternehmen genutzt werden kann. Dies verringert redundante Datenspeicherung und verbessert Genauigkeit und Konsistenz der Daten.
Um Datenintegration effektiv umzusetzen, helfen folgende Schritte:
- Anforderungen an die Datenintegration definieren: Klären Sie, welche Daten integriert werden müssen, woher sie stammen und wie sie genutzt werden.
- Datenintegrationsstrategie entwickeln: Skizzieren Sie Mapping, Transformation und Laden der Daten in einer Gesamtarchitektur.
- ETL-Tools einsetzen: Nutzen Sie ETL- oder Data-Automation-Tools, um Integrationsprozesse zu automatisieren und zu beschleunigen. Moderne DWA-Tools generieren ETL-Prozesse direkt als Prozeduren und Logik in der Datenbank.
- Datenqualitätsprüfungen implementieren: Stellen Sie über Profiling, Bereinigung und Standardisierung sicher, dass integrierte Daten korrekt, vollständig und konsistent sind.
- Data Virtualization verwenden: Erstellen Sie eine einheitliche Sicht auf Daten, ohne sie physisch zusammenzuführen. Data Virtualization ermöglicht den Zugriff auf verschiedene Quellen, als kämen sie aus einem System. DWA-Tools wie AnalyticsCreator bieten hierfür Architekturvorlagen mit einer physischen Ebene und automatisch generierten logischen Sichten.
- Master Data Management (MDM) implementieren: Schaffen Sie eine zentrale, autoritative Quelle für Stammdaten, um konsistente Informationen in allen Systemen sicherzustellen.
Effiziente Berichterstellung und Analyse ermöglichen
 Die Datenmodellierung ermöglicht eine effektive Berichterstellung und Analyse, indem sie ein klares Verständnis der Datenorganisation und -beziehungen liefert. Analysten können benötigte Daten schneller finden, korrekt kombinieren und zielgerichtet auswerten.
Die Datenmodellierung ermöglicht eine effektive Berichterstellung und Analyse, indem sie ein klares Verständnis der Datenorganisation und -beziehungen liefert. Analysten können benötigte Daten schneller finden, korrekt kombinieren und zielgerichtet auswerten.
Wichtige Schritte, um Reporting und Analytics zu unterstützen:
- Berichtsanforderungen definieren: Klären Sie, welche Berichte und Dashboards benötigt werden, wer sie nutzt und in welcher Frequenz.
- Berichtsstrategie entwickeln: Legen Sie fest, wie Daten extrahiert, transformiert und für Berichte bereitgestellt werden.
- Berichtstools nutzen: Setzen Sie geeignete BI-Tools ein, um Standardberichte, interaktive Dashboards und Visualisierungen zu erstellen, mit denen Anwender Erkenntnisse in die Geschäftsleistung gewinnen können.
- Datenvisualisierung implementieren: Visualisieren Sie komplexe Sachverhalte in Diagrammen, Graphen und anderen Visualisierungen, um Trends und Muster schnell zu erkennen.
- Self-Service-Analysen ermöglichen: Stellen Sie Self-Service-Analysetools bereit, mit denen Fachanwender eigene Berichte und Auswertungen erstellen können, ohne von der IT abhängig zu sein. Self-Service-Analytics funktioniert deutlich besser, wenn ein sauberes Data Warehouse als Basis existiert und nicht nur Cube-Lösungen.
- Datenqualität sicherstellen: Achten Sie auf genaue, vollständige und konsistente Daten. Schlechte Datenqualität untergräbt Berichte und Analysen – daher sind kontinuierliche Qualitätsprüfungen und Bereinigung essenziell.
Hauptpunkte
Die Datenmodellierung ist für den Erfolg eines Data-Warehouse-Projekts von entscheidender Bedeutung. Sie stellt sicher, dass die im Warehouse gespeicherten Daten genau, konsistent und gut strukturiert sind – die Grundlage für verlässliche, datengetriebene Entscheidungen.
Jede der genannten Datenmodellierungstechniken hat ihre eigenen Vor- und Nachteile, und die Wahl der passenden Methode hängt von den spezifischen Anforderungen Ihrer Organisation ab. Wichtig ist, dass Ihre Daten über einen langen Zeitraum hinweg genau, zuverlässig, gut organisiert, leicht zugänglich und sicher bleiben.
So erhöhen Sie den Wert Ihrer Daten, verbessern die Effektivität Ihrer Datenmanagementprozesse, reduzieren Fehler und schaffen eine einheitliche Sicht auf Informationen in Ihrer Organisation. Wenn Reporting- und Analyseinitiativen auf dieser Basis aufbauen, haben Anwender genau die Daten zur Hand, die sie benötigen, um fundierte Entscheidungen zu treffen – schnell, transparent und belastbar.