
With an ever-evolving modern data stack, there are plenty of options to approach data architectures and platforms. Designing and implementing a metadata-driven framework for analytics to dynamically manage a Data Warehouse (or Data Lakehouse) is essential.
Business data sources and needs are constantly growing and changing. Traditionally, handling these changes involved team discussions, manual pipeline edits, adding or removing columns, and multiple iterations to finalize solutions. This can be inefficient, create errors, and lead to inconsistent pipelines that become difficult for teams to understand and maintain.
Key Components of a Dynamic Data Warehouse Metadata Framework
A metadata framework is a set of rules, standards, and guidelines for describing and organizing data within an organization. It defines how data elements are identified, classified, and documented. A well-designed data warehouse metadata framework includes several components working together to ensure governance, clarity, and structure:

- Metadata Repository: This acts as the centralized storage for all technical metadata about the data warehouse. It houses information such as:
- Data sources (e.g., databases, applications)
- Transformations applied to the data (e.g., filtering, aggregation)
- Table structures (columns, data types)
- Relationships between different data elements
- Code
Think of it as the data dictionary for your data warehouse, ensuring consistency and offering a single source of truth for data-related details.

- Data Catalog: While the metadata repository stores the technical details, the data catalog offers a user-friendly interface and search functionality on top of it. This allows users with varying technical backgrounds, including business analysts, data scientists, and even non-technical stakeholders, to:
- Discover relevant data assets based on their specific needs.
- Understand the data through clear descriptions and lineage information.
- Easily access the data for further analysis or reporting.
The data catalog acts as a searchable index within the framework, making data exploration and understanding more accessible for a broader audience.

- Data Lineage and Impact Analysis: This component tracks the flow of data throughout the data pipeline, allowing you to:
- Identify bottlenecks or potential issues within the pipeline.
- Analyze the downstream consequences of changes made to the data to ensure data integrity and optimize pipeline efficiency.

- Version Control: This functionality allows you to track changes made to the data warehouse, enabling you to:
- Revert to previous versions if necessary.
- Ensure everyone is working with the latest version of the data and metadata.
These components collectively support a robust and well-organized metadata framework, empowering organizations to manage data efficiently and make informed decisions.
Understanding the Importance and Benefits of a Metadata Framework
Traditional data warehouse management relies heavily on manual processes and siloed information—approaches that are increasingly inefficient as data grows in scale and complexity. A strong metadata framework addresses these challenges and provides significant benefits:
- Empower informed decision-making: Clear lineage, standardized documentation, and transparency allow users to confidently analyze data without risk of misinterpretation.
- Ensure data quality and consistency: Standardized definitions, structures, and automated processes maintain integrity across the pipeline.
- Improve data management efficiency: Automation reduces manual tasks, letting teams focus on strategy and analysis.
- Enhance data governance and compliance: Clear ownership, traceability, and usage documentation support responsible data practices and regulatory alignment.
Benefits of Using AnalyticsCreator for Building a Metadata Framework
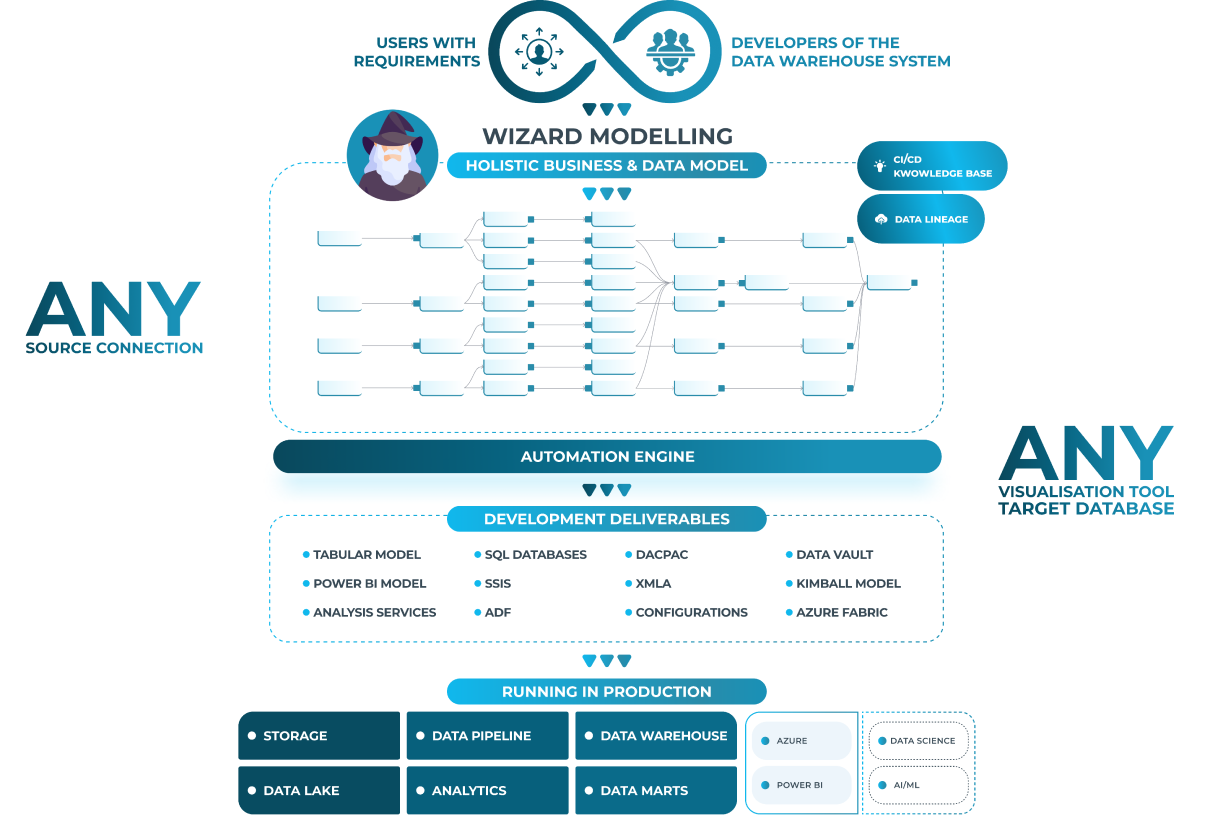
AnalyticsCreator is an application builder for Data and Analytics. Through its GUI, users build business and data models from the source layer upward. AC extracts metadata and generates a data catalog, which the Data Wizard uses to automatically produce best-practice code for the entire data environment and metadata framework. Any changes made to the graphical model dynamically update the generated assets.
Users can leverage the built-in metadata repository to build both business and data models. All information is stored centrally, enabling automated code generation specific to target systems and deployment needs.
- Ease of Use: Intuitive, visual interface accessible to technical and non-technical users.
- Automation and Efficiency: Reusable templates and rules reduce manual effort and maintenance.
- Scalability and Flexibility: Supports diverse data sources and large data volumes.
- GUI for Metadata Framework: All metadata—catalog, cubes, framework, and DWH—is dynamically updated with model changes.
Comprehensive Data Model and Documentation
- Holistic Data Model: Full view of entities and relationships for organized metadata.
- Automated Model Generation: Generates code with descriptions and lineage metadata.
- Customizable Templates: Supports Kimball, Data Vault, and other models, including generation from source metadata.
- Holistic Data View: Changes made anywhere (tables or columns) update globally across the metadata framework.

Streamlined Data Management and Governance
- Centralized Repository: Manages the complete data warehouse lifecycle from a single platform.
- User Access and Permissions: Defines role-based access to ensure secure metadata handling.
- Version Control and Audit Trails: Automatically tracks changes for full transparency and governance.
Integration and Flexibility
- Extensive Data Source Support: Captures metadata from many systems.
- Custom Connectivity: Add connectors and metadata definitions for custom or legacy sources.
- Flexible Data Export: Export models to SQL, JSON, and more.
- Custom Code Extensions: Automate repetitive tasks through code snippets.
Data Lineage and Governance
- Transparency and Trust: Lineage visualizations clarify data provenance.
- Improved Data Governance: Supports compliance with auditable data flows.
- Efficient Impact Analysis: Understand downstream impact of changes instantly.
- Enhanced Framework Completeness: Lineage shows not only "what" data exists, but "how" and "why" it changes.
- Continuous Optimization: Identify pipeline issues and optimize flow.

Steps to Create a Powerful Metadata Framework in AnalyticsCreator
- Define Scope and Objectives: Identify key data needs and stakeholder expectations.
- Design the Metadata Model: Define entities, attributes, and relationships visually.
- Configure Data Sources and Transformations: Integrate sources, apply transformations, and reuse templates.
- Implement Version Control and Data Lineage: Use built-in features for governance and traceability.
- Generate Warehouse Code and Deploy: Best-practice code is generated dynamically using the model.
- Test and Deploy: Validate model accuracy and performance before production rollout.
Configuring Data Sources and Transformations
- Data Discovery: Explore and understand available data sources.
- Transformation Functions: Apply built-in data quality and transformation logic.
- Profiling: Assess data quality, distributions, and anomalies before integrating.
Implementing Version Control and Lineage
- Version Control: Track changes, revert versions, and maintain governance.
- Lineage Visualization: View transformation paths and dependencies for clarity and troubleshooting.
Testing and Deployment
- Testing: Validate model behavior and metadata accuracy.
- Metadata Export: Export metadata for deployment in multiple environments.
Conclusion
A metadata-driven approach is transformative for managing modern Data Warehouses. Tools like AnalyticsCreator streamline processes, enhance governance, improve data quality, and support scalability. With dynamic metadata updates, lineage visualizations, and automated best-practice code generation, organizations gain transparency and control—unlocking the full potential of their data.